NeRF-US trains a NeRF on sound fields.
Novel view ultrasound renders from NeRF-US.
Abstract
Motivation

How does NeRF-US work?
Our goal is to produce a 3D representation given a set of ultrasound images taken in the wild and their camera positions. The first step of our approach relies on the training of a 3D diffusion model, which can serve as geometric priors for our NeRF model. This diffusion model produces an 32 x 32 x 32 occupancy grid. To create this diffusion model, we finetune the 3D diffusion model on a small dataset of voxels around the human knee generated synthetically.
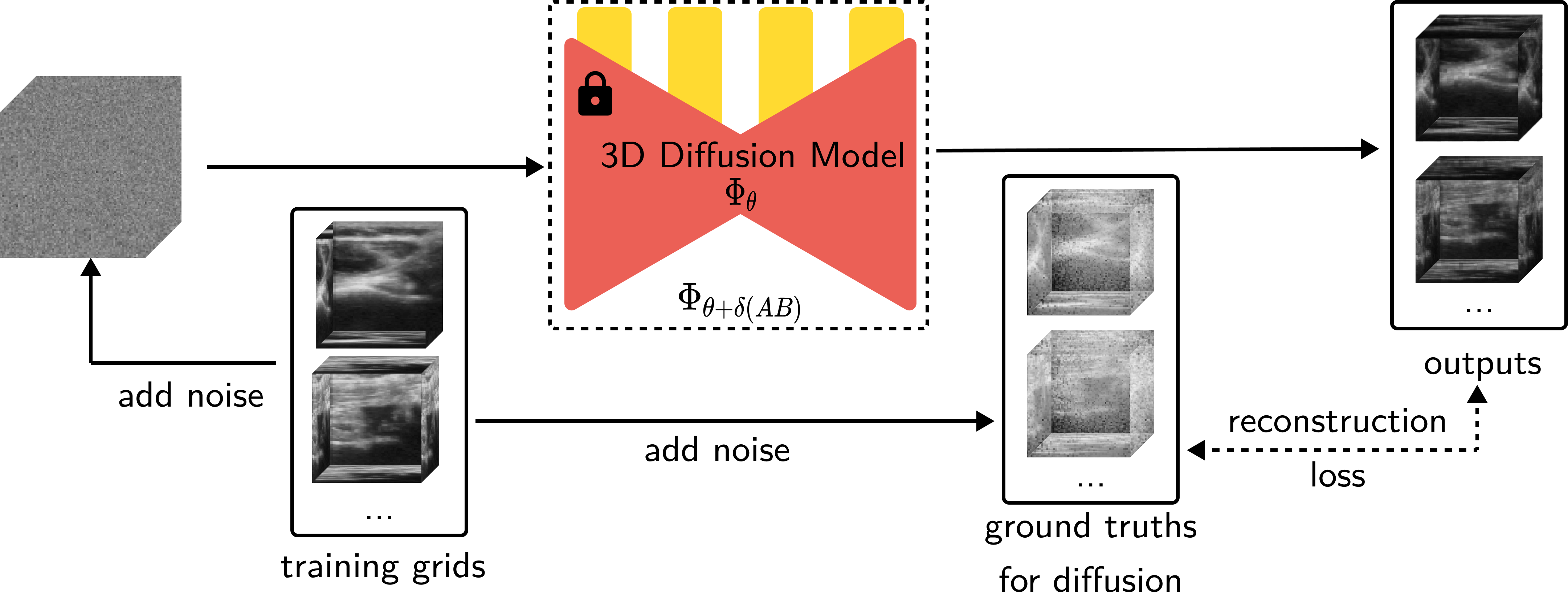
Figure: An overview of how our diffusion model is fine-tuned, we use 323-sized patches to LoRA-finetune a 3D diffusion model trained on ShapeNet.
We now train our NeRF model that takes in a 3D vector (denoting positions in 3D) and learns a 5D vector (attenuation, reflectance, border probability, scattering density, and scattering intensity). While training this NeRF, we run the outputs through the diffusion model and obtain guidance vectors for border probability and scattering density. These are added to the photometric loss. We finally train the NeRF with this final loss we calculated.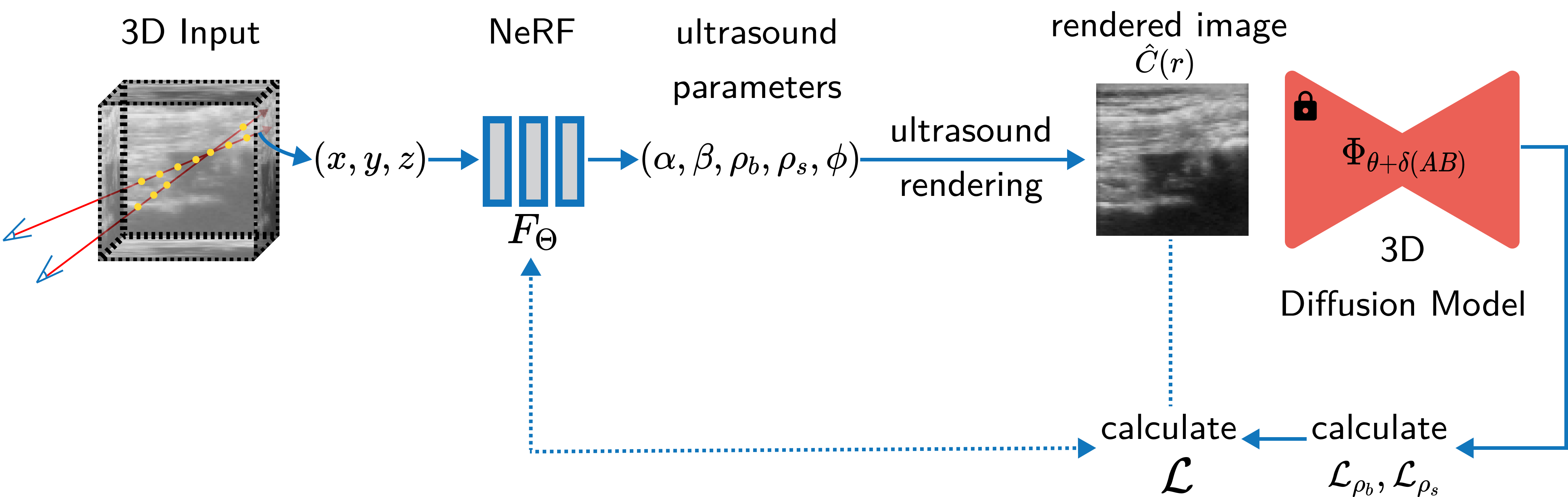
Figure: An overview of how our method works. We train a NeRF model that uses ultrasound rendering to convert the representations into a 2D image after which we infer through a 3D diffusion model which has geometry priors through which we calculate a modified loss definition to train the NeRF.
Visual Results
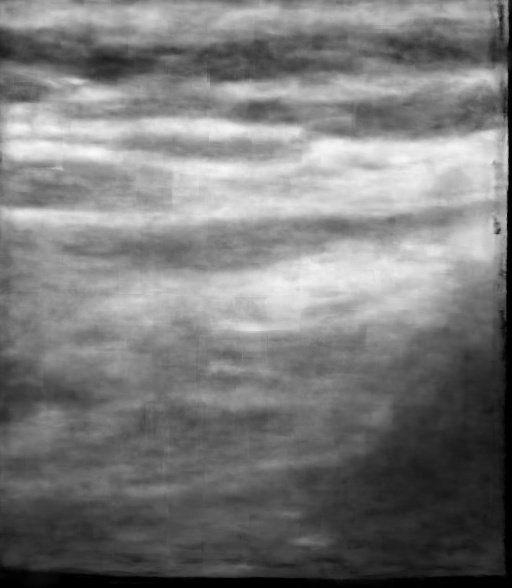
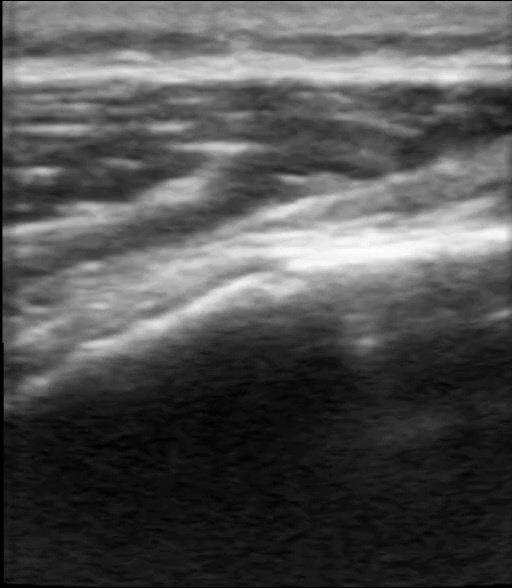

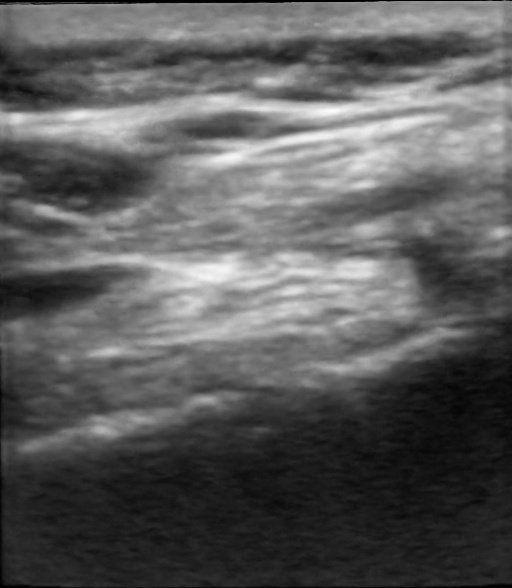
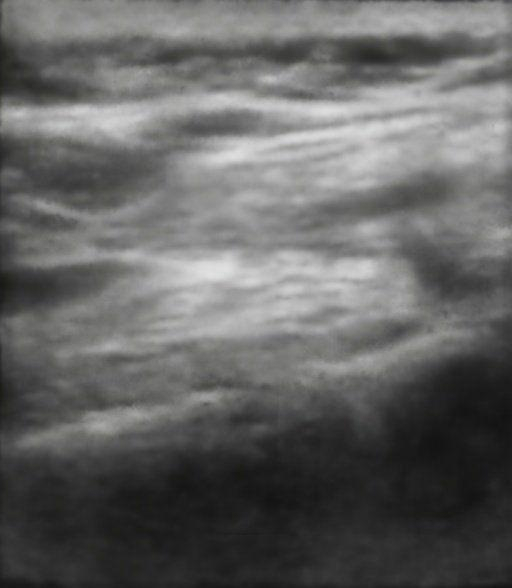
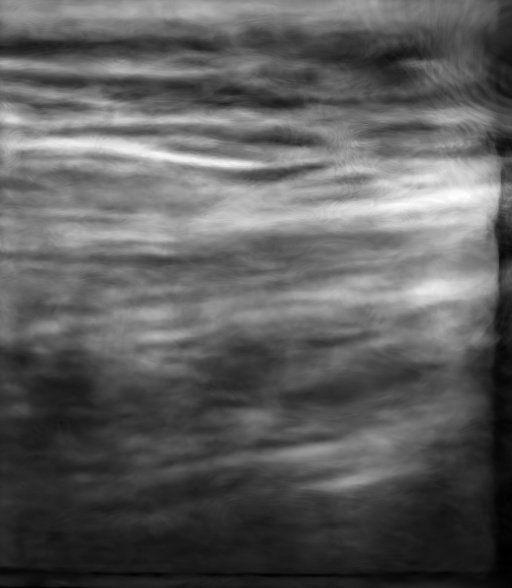
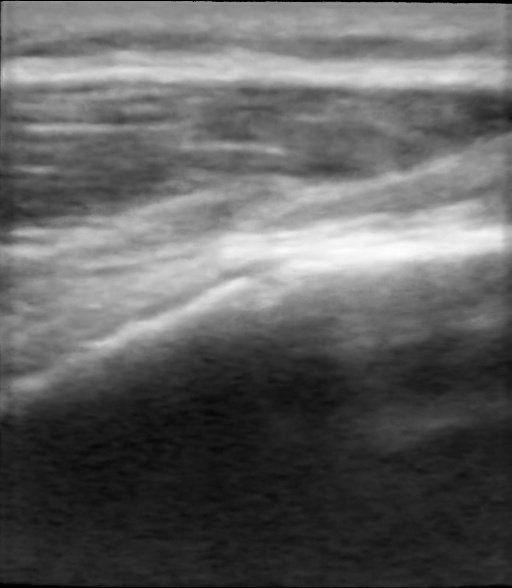
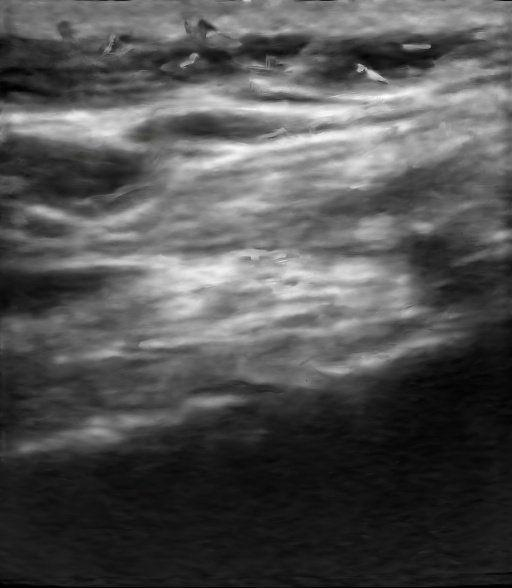
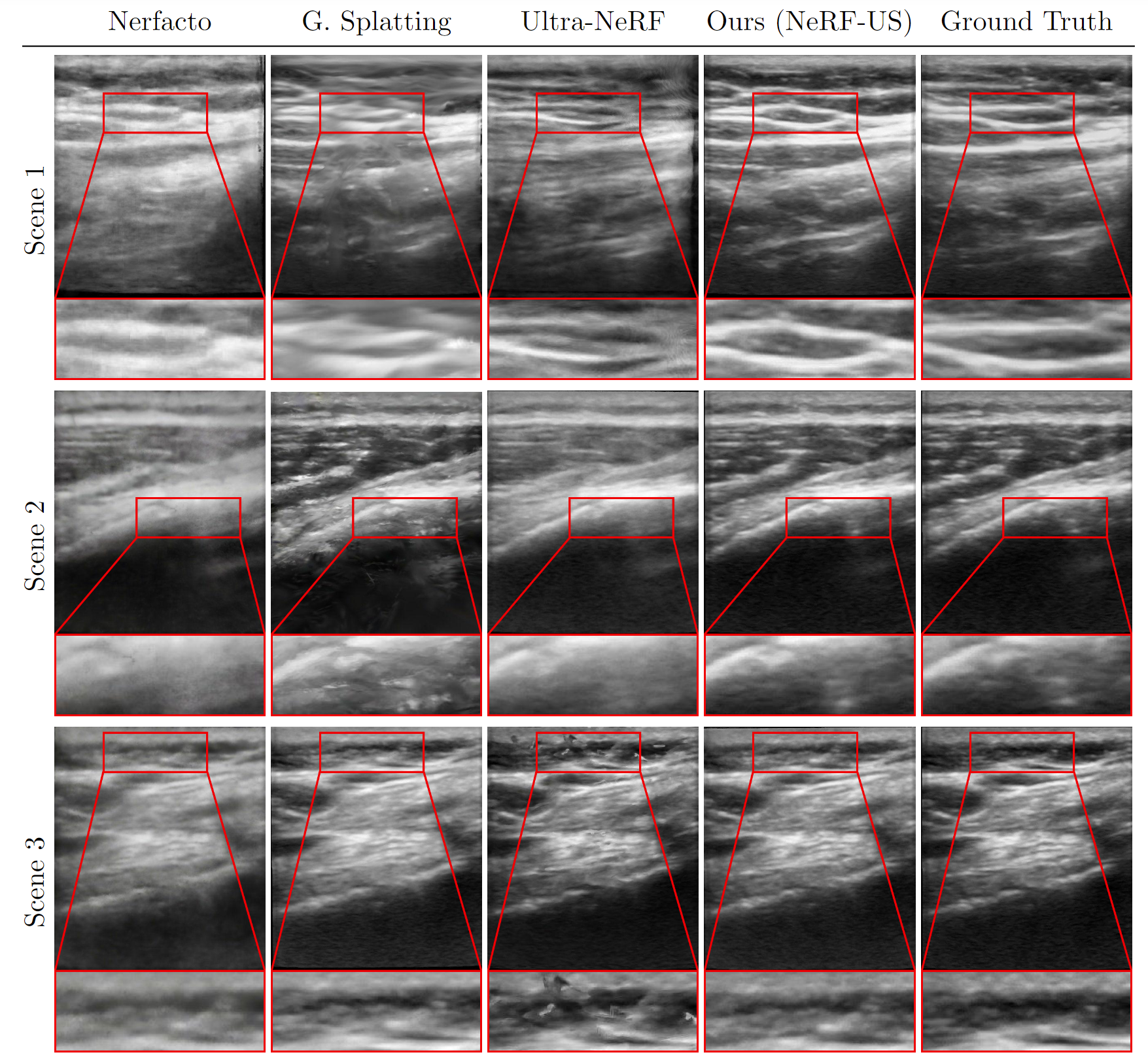
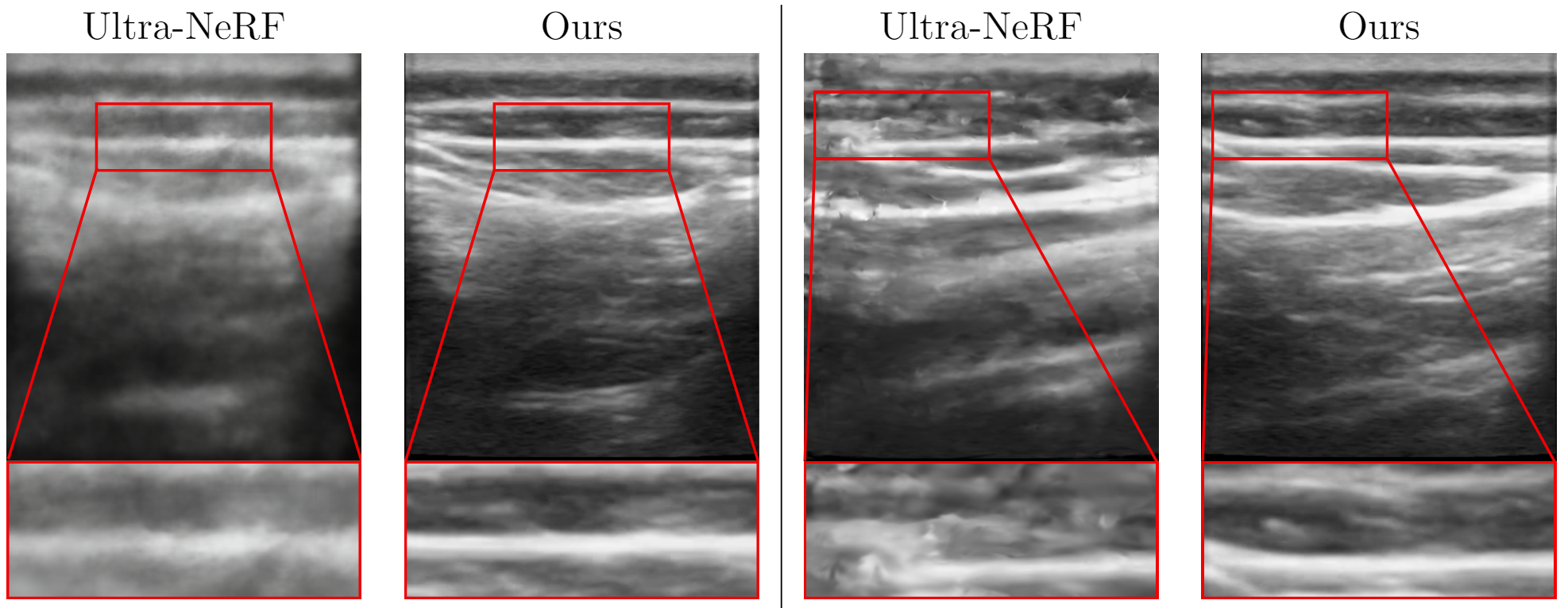
Figure: Qualitative Results. We demonstrate the results of our method and compare it qualitatively with Nerfacto [1], Gaussian Splatting [3], and Ultra-NeRF [2]. Our approach, NeRF-US, produces accurate and high-quality reconstructions as compared to the baseline models on novel views (best viewed with zoom).
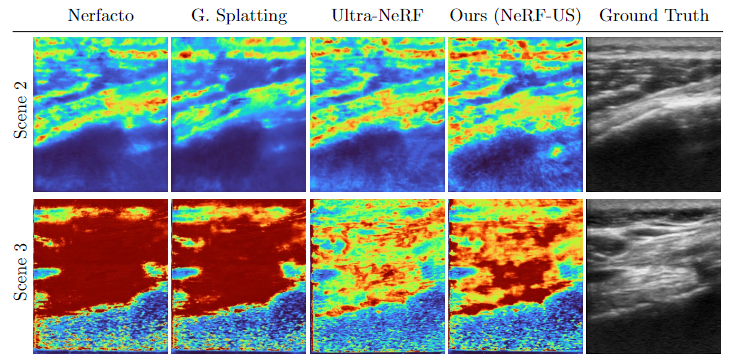
Figure: Qualitative Results. We demonstrate the results of depth maps produced from our method and compare them qualitatively with Nerfacto [1], Gaussian Splatting [3], and Ultra-NeRF [2] (best viewed in color and with zoom).
Ultrasound in the wild Dataset
Here we show some instances of our new ultrasound in the wild dataset, we limit the visualizations of the dataset to the first 10 seconds of some of the scenes in our dataset. For visualization, we pre-process these videos with a script.Examples from our ultrasound in the wild dataset.
Related Links
The following works were mentioned on this page:[1] Tancik, Matthew, et al. "Nerfstudio: A modular framework for neural radiance field development." ACM SIGGRAPH 2023 Conference Proceedings. 2023.
[2] Wysocki, Magdalena, et al. "Ultra-nerf: neural radiance fields for ultrasound imaging." Medical Imaging with Deep Learning. PMLR, 2024.
[3] Kerbl, Bernhard, et al. "3d gaussian splatting for real-time radiance field rendering." ACM Transactions on Graphics 42.4 (2023): 1-14.
Citation
@misc{dagli2024nerfusremovingultrasoundimaging,
title={NeRF-US: Removing Ultrasound Imaging Artifacts from Neural Radiance Fields in the Wild},
author={Rishit Dagli and Atsuhiro Hibi and Rahul G. Krishnan and Pascal N. Tyrrell},
year={2024},
eprint={2408.10258},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.10258},
}